Research
Data-Driven Discovery
Genevera’s group develops new statistical machine learning tools to help people make reliable discoveries from large and complex data sets, especially in neuroscience and biomedicine.
Research Areas
Statistical Machine Learning
Graphical Models
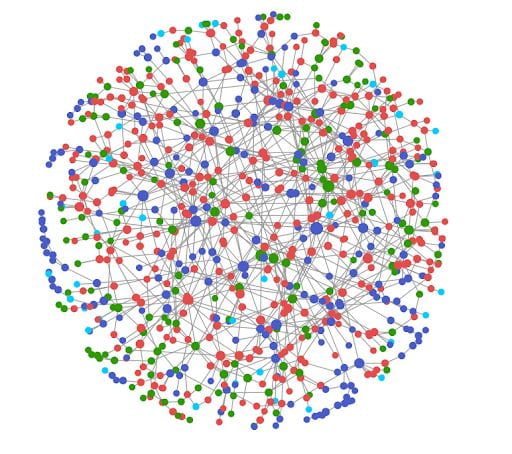
We develop new types of probabilistic graphical models and graph learning strategies for representing, discovering, and visualizing relationships in large data sets. Our work includes developing new classes of graphical models for diverse data types and multi-modal data as well as new graph learning strategies to tackle challenges encountered in neuroscience and beyond.
Key Publications:
- E. Yang, P. Ravikumar, G. I. Allen, and Z. Liu, “Graphical Models via Univariate Exponential Family Distributions”, Journal of Machine Learning Research, 16:3813-3847, 2015. link
- E. Yang, Y. Baker, P. Ravikumar, G. I. Allen, and Z. Liu, “Mixed Graphical Models via Exponential Families”, In Artificial Intelligence and Statistics (AISTATS), oral presentation, 2014. link
- L. Zheng and G. I. Allen, “Graphical Model Inference with Erosely Measured Data”, (To Appear) Journal of American Statistical Association: Theory & Methods, arXiv:2210.11625, 2023. link
- M. Wang and G. I. Allen, “Thresholded Graphical Lasso Adjusts for Latent Variables”, Biometrika, 110:3, 681-697, 2023. link
- G. Vinci, G. Dasarathy, and G. I. Allen, “Graph Quilting: Graphical Model Selection from Partially Observed Covariances”, arXiv:1912.05573, 2020. link
- E. Yang, P. Ravikumar, G. I. Allen, and Z. Liu, “On Poisson Graphical Models”, In Advances in Neural Information Processing Systems (NeurIPS), 2013. link
- A. Chang and G. I. Allen, “Subbotin Graphical Models for Extreme Value Dependencies with Applications to Functional Neuronal Connectivity”, Annals of Applied Statistics, 17:3, 2364-2386, 2023. link
Data Integration
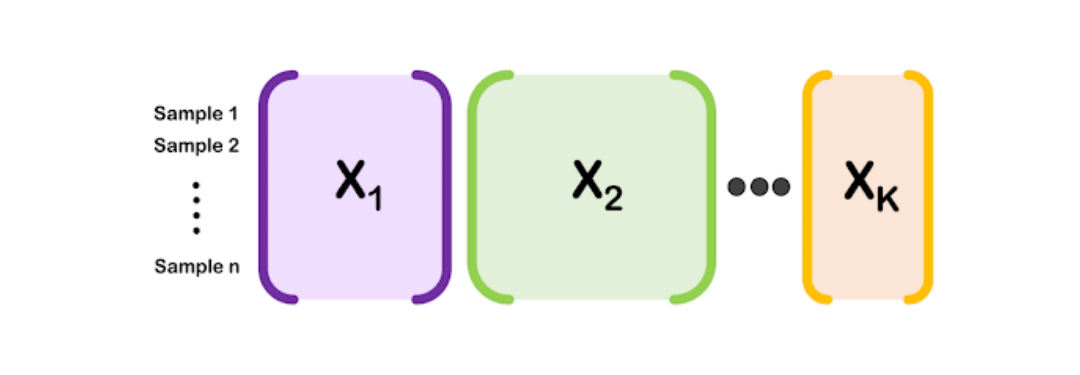
Large data sets are often diverse, with multiple types of features measured on the same set of subjects or observations. We have developed a variety of interpretable machine learning techniques for discovering joint patterns in this so-called mixed multi-modal data.
Key Publications:
- T. M. Tang and G. I. Allen, “Integrated Principal Components Analysis”, Journal of Machine Learning Research, 22:198, 1-71, 2021. link
- M. Wang and G. I. Allen, “Integrative Generalized Convex Clustering Optimization and Feature Selection for Mixed Multi-View Data”, Journal of Machine Learning Research, 22:1-73, 2021. link
- Y. Baker, T. M. Tang, and G. I. Allen, “Feature Selection for Data Integration with Mixed Multiview Data”, Annals of Applied Statistics, 14:4, 1676-1698, 2020. link
- J. Liu, L. Zheng, Z. Zhang, and G. I. Allen, “Joint Semi-Symmetric Tensor PCA for Integrating Multi-modal Populations of Networks”, arXiv:2312.14416, 2023. link
- Y. W. Wan, G. I. Allen, and Z. Liu, “TCGA2STAT: Simple TCGA Data Access for Integrated Statistical Analysis in R”, Bioinformatics, 32:6, 952-954, 2016. link
- E. Yang, Y. Baker, P. Ravikumar, G. I. Allen, and Z. Liu, “Mixed Graphical Models via Exponential Families”, In Artificial Intelligence and Statistics (AISTATS), oral presentation, 2014. link
Clustering
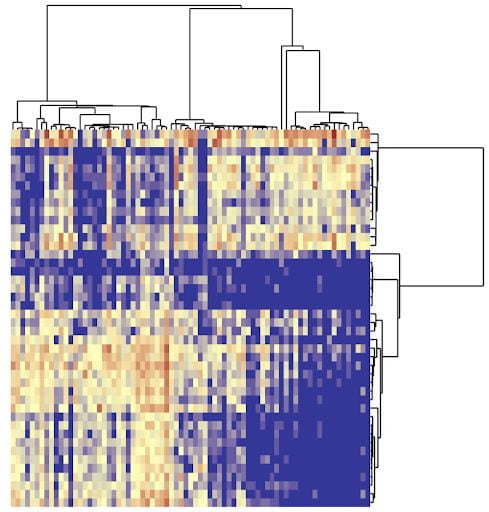
Clustering seeks to find groups in large data sets. We have developed several convex clustering approaches that offer reliable, principled, and flexible strategies along with built-in visualizations for clustering.
Key Publications:
- E. C. Chi, G. I. Allen, and R. Baraniuk, “Convex Biclustering”, Biometrics, 73:1, 10-19, 2017. link
- M. Weylandt, J. Nagorski, and G. I. Allen, “Dynamic Visualization and Fast Computation for Convex Clustering via Algorithmic Regularization”, Journal of Computational and Graphical Statistics, 29:1, 87-96, 2020. link
- M. Wang and G. I. Allen, “Integrative Generalized Convex Clustering Optimization and Feature Selection for Mixed Multi-View Data”, Journal of Machine Learning Research, 22:1-73, 2021. link
- Y. Baker, T. M. Tang, and G. I. Allen, “Feature Selection for Data Integration with Mixed Multiview Data”, Annals of Applied Statistics, 14:4, 1676-1698, 2020. link
- L. Gan and G. I. Allen, “Fast and Interpretable Consensus Clustering via Minipatch Learning”, PLoS Computational Biology, 18:10, e1010577, 2022. link
- M. Wang, T. Yao, and G. I. Allen, “Supervised Convex Clustering”, Biometrics, 79:4, 3846-3858, 2023. link
- L. Zheng, A. Chang, and G. I. Allen, “Cluster Quilting: Spectral Clustering for Patchwork Learning”, arXiv:2406.13833, 2024. link
Dimension Reduction
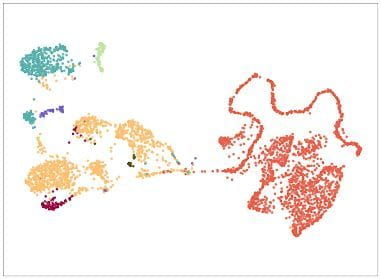
Dimension reduction techniques are used for visualizing, exploring, and discovering patterns in large data sets. We have developed many dimension reduction techniques for complex and structured data; these include sparse tensor decompositions and generalizations of PCA for structured or multi-modal data.
Key Publications:
- G. I. Allen, L. Grosenick and J. Taylor, “A Generalized Least Squares Matrix Decomposition”, Journal of the American Statistical Association: Theory and Methods, 109:505, 145-159, 2014. link
- G. I. Allen, “Sparse Higher-Order Principal Components Analysis”, In Artificial Intelligence and Statistics (AISTATS), 27-36, 2012. link
- T. M. Tang and G. I. Allen, “Integrated Principal Components Analysis”, Journal of Machine Learning Research, 22:198, 1-71, 2021. link
- G. I. Allen, and M. Weylandt, “Sparse and Functional Principal Components Analysis”, In Proceedings of the IEEE Data Science Workshop, 2019. link
- G. I. Allen and M. Maletic-Savatic, “Sparse Non-negative Generalized PCA with Applications to Metabolomics”, Bioinformatics, 27:21, 3029-3035, 2011. link
- J. Liu, L. Zheng, Z. Zhang, and G. I. Allen, “Joint Semi-Symmetric Tensor PCA for Integrating Multi-modal Populations of Networks”, arXiv:2312.14416, 2023. link
Sparsity & High-Dimensional Statistics
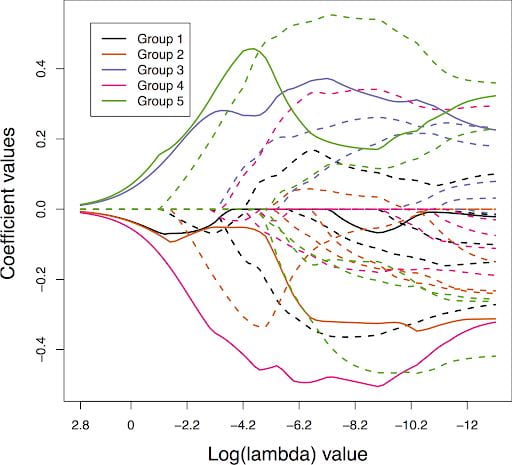
Much of our research lies in the area of high-dimensional statistics, where the number of features exceeds the number of samples. A major focus in this area is on sparsity and structured sparsity to enhance feature selection and interpretability.
Key Publications:
- F. Campbell and G. I. Allen, “Within Group Variable Selection through the Exclusive Lasso”, Electronic Journal of Statistics, 11:2, 4220-4257, 2017. link
- G. I. Allen, “Automatic Feature Extraction via Weighted Kernels and Regularization”, Journal of Computational and Graphical Statistics, 22:2, 284-299, 2013. link
- Y. Baker, T. M. Tang, and G. I. Allen, “Feature Selection for Data Integration with Mixed Multiview Data”, Annals of Applied Statistics, 14:4, 1676-1698, 2020. link
- A. Chang, M. Wang, and G. I. Allen, “Sparse Regression for Extreme Values”, Electronic Journal of Statistics, 15:2, 5995-6035, 2021. link
- Y. Hu, E. C. Chi, and G. I. Allen, “ADMM Algorithmic Regularization Paths for Sparse Statistical Learning”, In Splitting Methods in Communication and Imaging, Science and Engineering, R. Glowinski, W. Yin, and S. Osher (eds), Springer, 433-459, 2016. link
Tensors
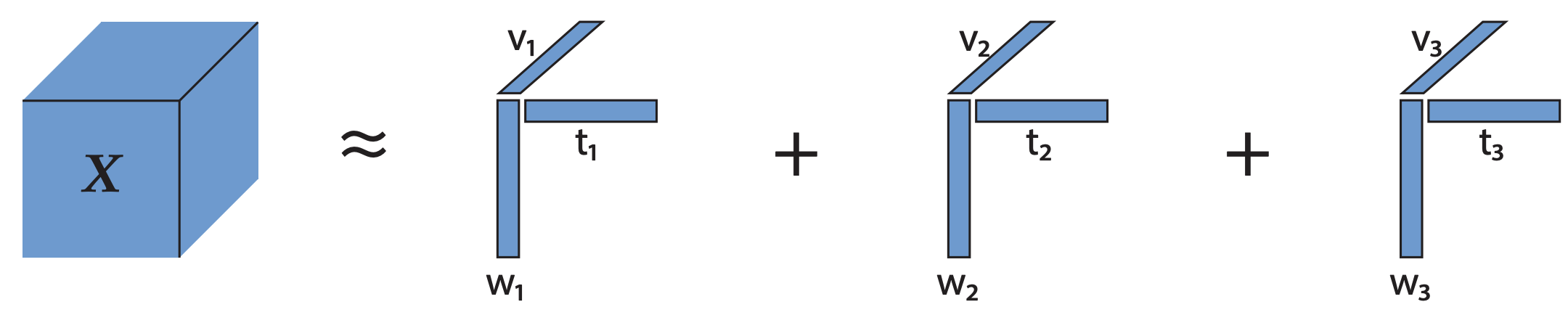
Directly working with tensor, or multi-way array, data yields many computational and statistical advantages. Our work has focused on developing interpretable tensor decomposition strategies with applications in neuroscience, chemometrics, and genomics.
Key Publications:
- G. I. Allen, “Sparse Higher-Order Principal Components Analysis”, In Artificial Intelligence and Statistics (AISTATS), 27-36, 2012. link
- G. I. Allen, “Multi-way Functional Principal Components Analysis”, In IEEE International Workshop on Computational Advances in Multi-Sensor Adaptive Processing, 2013. link
- Z. Zhang, G. I. Allen, H. Zhu, D. Dunson, “Tensor Network Factorizations: Relationships between Human Brain Structural Connectomes and Traits”, NeuroImage, 197:330-343, 2019. link
- J. Liu, L. Zheng, Z. Zhang, and G. I. Allen, “Joint Semi-Symmetric Tensor PCA for Integrating Multi-modal Populations of Networks”, arXiv:2312.14416, 2023. link
- K. Geyer, F. Campbell, A. Chang, J. Magnotti, M. Beauchamp, G. I. Allen, “Interpretable Visualization and Higher-Order Dimension Reduction for ECoG Data”, In Proceedings of the The International Workshop on Big Data Reduction held with the 2020 IEEE International Conference on Big Data, 2020. link
Ensemble Learning
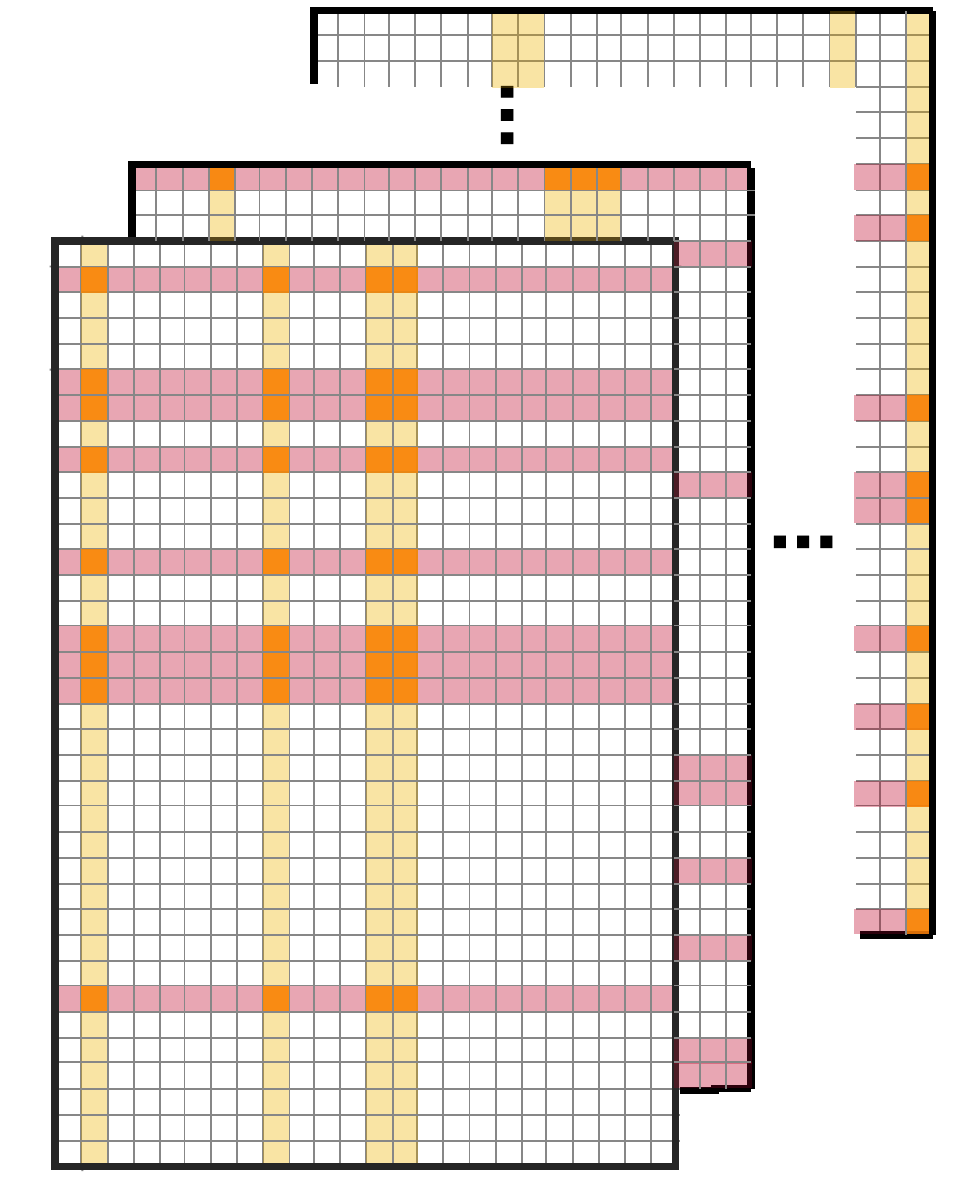
Recently, we have begun developing new computationally efficient ensemble learning strategies called minipatch learning that also lead to improved statistical properties and interpretability.
Key Publications:
- T. Yao, D. LeJeune, H. Javadi, R. G. Baraniuk, and G. I. Allen, “Minipatch Learning as Implicit Ridge-Like Regularization”, In IEEE International Conference on Big Data and Smart Computing (BigComp), 2021. link
- M. T. Toghani and G. I. Allen, “MP-Boost: Minipatch Boosting via Adaptive Feature and Observation Sampling”, In IEEE International Conference on Big Data and Smart Computing (BigComp), 2021. link
- L. Gan and G. I. Allen, “Fast and Interpretable Consensus Clustering via Minipatch Learning”, PLoS Computational Biology, 18:10, e1010577, 2022. link
- L. Gan, L. Zheng, and G. I. Allen, “Model-Agnostic Confidence Intervals for Feature Importance: A Fast and Powerful Approach Using Minipatch Ensembles”, arXiv:2206.02088, 2022. link
- T. Yao, M. Wang, and G. I. Allen, “Fast and Accurate Graph Learning for Huge Data via Minipatch Ensembles”, arXiv:2110.12067, 2021. link
Quilting & Patchwork Learning
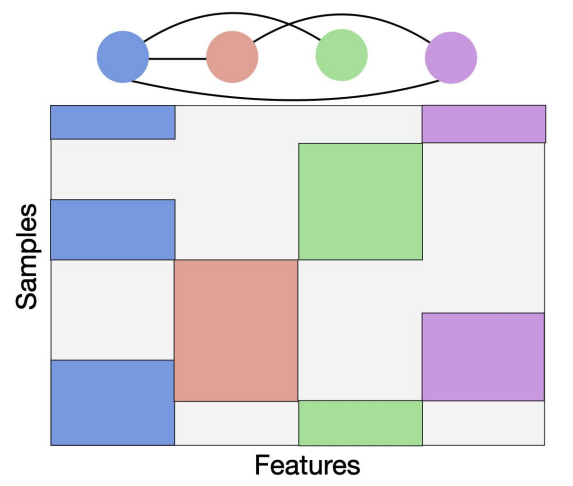
In neuroscience, data integration, causal panel data and more, we often observe data in patches or blocks with huge portions of data that is not missing at random. We recently have developed new unsupervised approaches in this patchwork learning setting.
Key Publications:
- G. Vinci, G. Dasarathy, and G. I. Allen, “Graph Quilting: Graphical Model Selection from Partially Observed Covariances”, arXiv:1912.05573, 2020. link
- A. Chang, L. Zheng and G. I. Allen, “Low-Rank Covariance Completion for Graph Quilting with Applications to Functional Connectivity”, arXiv:2209.08273, 2022. link
- L. Zheng and G. I. Allen, “Graphical Model Inference with Erosely Measured Data”, (To Appear) Journal of American Statistical Association: Theory & Methods, arXiv:2210.11625, 2023. link
- A. Chang, L. Zheng, G. Dasarthy, G. I. Allen, ”Nonparanormal Graph Quilting with Applications to Calcium Imaging”, Stat, 12:1, e623, 2023. link
- L. Zheng, A. Chang, and G. I. Allen, “Cluster Quilting: Spectral Clustering for Patchwork Learning”, arXiv:2406.13833, 2024. link
Neuroscience
Connectomics
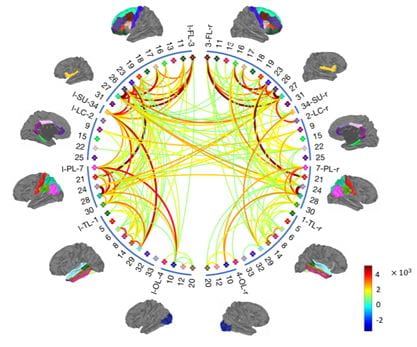
Connectomics seeks to understand how brain regions or neurons are structurally and functionally connected. Our research has focused on two aspects: developing new techniques to discover patterns in connectomics data and developing new techniques to learn functional connections from neural activity.
Key Publications:
- M. Narayan and G. I. Allen, “Mixed Effects Models for Resampled Network Statistics Improves Statistical Power to Find Differences in Multi-Subject Functional Connectivity” Frontiers in Neuroscience, 10:108, 2016. link
- S. Tomson, M. Narayan, G. I. Allen, D. Eagleman, “Neural Networks of Synesthesia”, Journal of Neuroscience, 33:35, 14098-14106, 2013. link
- S. Tomson, M. Schreiner, M. Narayan, T. Rosser; N. Enrique, A. J. Silva, G. I. Allen, S. Y. Bookheimer, and C. Bearden, “Resting state functional MRI reveals abnormal network connectivity in Neurofibromatosis 1”, Human Brain Mapping, 36:11, 4566-4581, 2015. link
- M. Wang and G. I. Allen, “Thresholded Graphical Lasso Adjusts for Latent Variables”, Biometrika, 110:3, 681-697, 2023. link
- G. Vinci, G. Dasarathy, and G. I. Allen, “Graph Quilting: Graphical Model Selection from Partially Observed Covariances”, arXiv:1912.05573, 2020. link
- A. Chang, L. Zheng and G. I. Allen, “Low-Rank Covariance Completion for Graph Quilting with Applications to Functional Connectivity”, arXiv:2209.08273, 2022. link
- A. Chang and G. I. Allen, “Subbotin Graphical Models for Extreme Value Dependencies with Applications to Functional Neuronal Connectivity”, Annals of Applied Statistics, 17:3, 2364-2386, 2023. link
- T. Yao, M. Wang, and G. I. Allen, “Fast and Accurate Graph Learning for Huge Data via Minipatch Ensembles”, arXiv:2110.12067, 2021. link
- A. Chang, T. Yao, and G. I. Allen, “Graphical Models and Dynamic Factor Models for Modeling Functional Brain Connectivity”, In Proceedings of the IEEE Data Science Workshop, 2019. link
- Z. Zhang, G. I. Allen, H. Zhu, D. Dunson, “Tensor Network Factorizations: Relationships between Human Brain Structural Connectomes and Traits”, NeuroImage, 197:330-343, 2019. link
Pattern Discovery
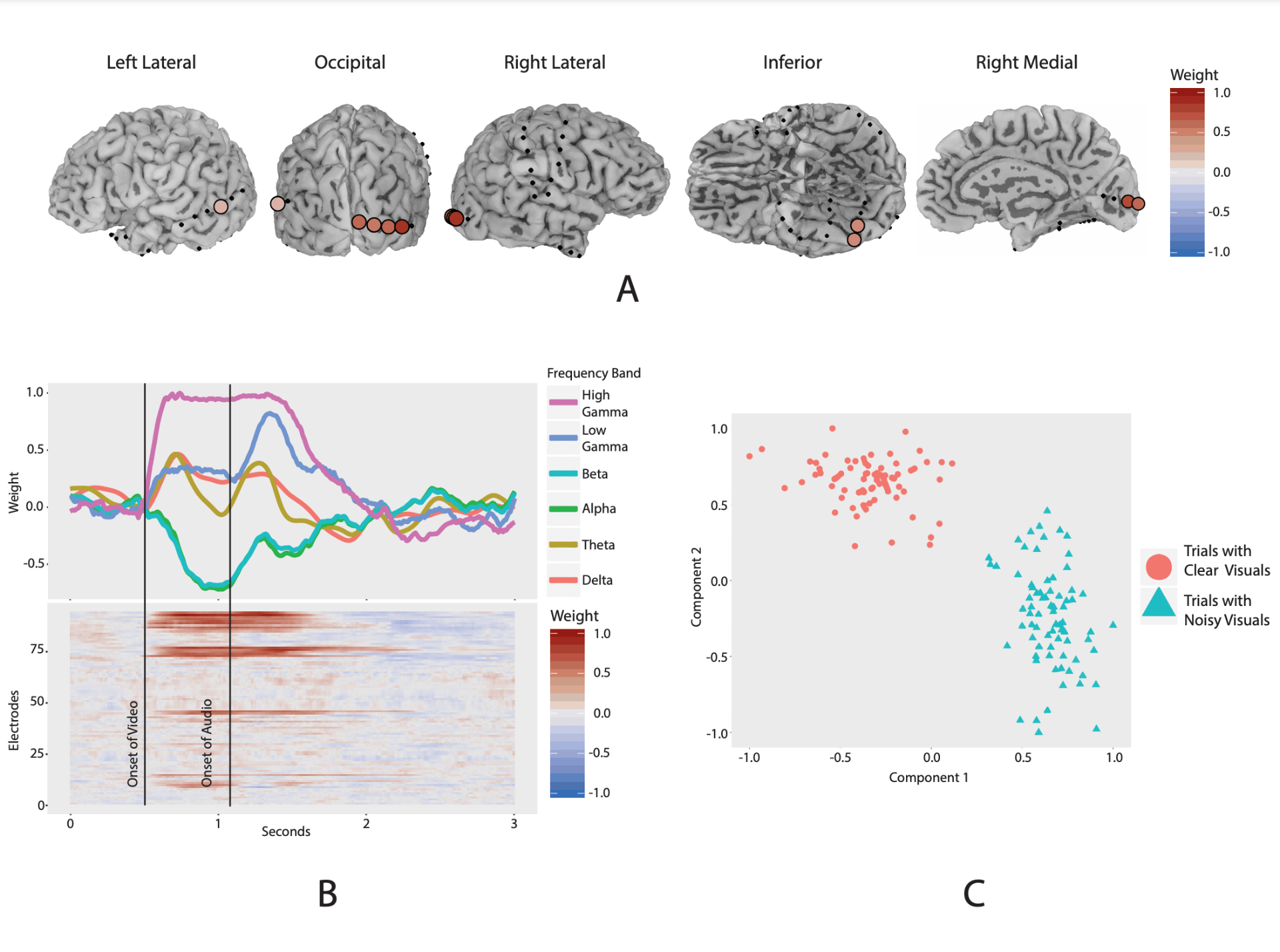
Our research seeks to discover scientifically interpretable patterns from large-scale neuroscience data using a combination of statistical and interpretable machine learning approaches. We have applied our techniques to many types of macro and micro-scale recording and imaging technologies including MRI, functional MRI, diffusion imaging, EEG, PET, ECoG, calcium imaging, spike trains, and many more.
Key Publications:
- Z. Zhang, G. I. Allen, H. Zhu, D. Dunson, “Tensor Network Factorizations: Relationships between Human Brain Structural Connectomes and Traits”, NeuroImage, 197:330-343, 2019. link
- K. Geyer, F. Campbell, A. Chang, J. Magnotti, M. Beauchamp, G. I. Allen, “Interpretable Visualization and Higher-Order Dimension Reduction for ECoG Data”, In Proceedings of the The International Workshop on Big Data Reduction held with the 2020 IEEE International Conference on Big Data, 2020. link
- J. Liu, L. Zheng, Z. Zhang, and G. I. Allen, “Joint Semi-Symmetric Tensor PCA for Integrating Multi-modal Populations of Networks”, arXiv:2312.14416, 2023. link
- G. I. Allen, and M. Weylandt, “Sparse and Functional Principal Components Analysis”, In Proceedings of the IEEE Data Science Workshop, 2019. link
- Y. Hu and G. I. Allen, “Local-Aggregate Modeling for Big-Data via Distributed Optimization: Applications to Neuroimaging”, Biometrics, 71:4, 905-917, 2015. link
- . T. Yao, E. M. Sweeney, J. Nagorski, J. Shulman, and G. I. Allen, “Quantifying cognitive resilience in Alzheimer’s Disease: The Alzheimer’s Disease Cognitive Resilience Score”, PLoS One, 15:11, e0241707, 2020. link
AI Ethics
Interpretable Machine Learning
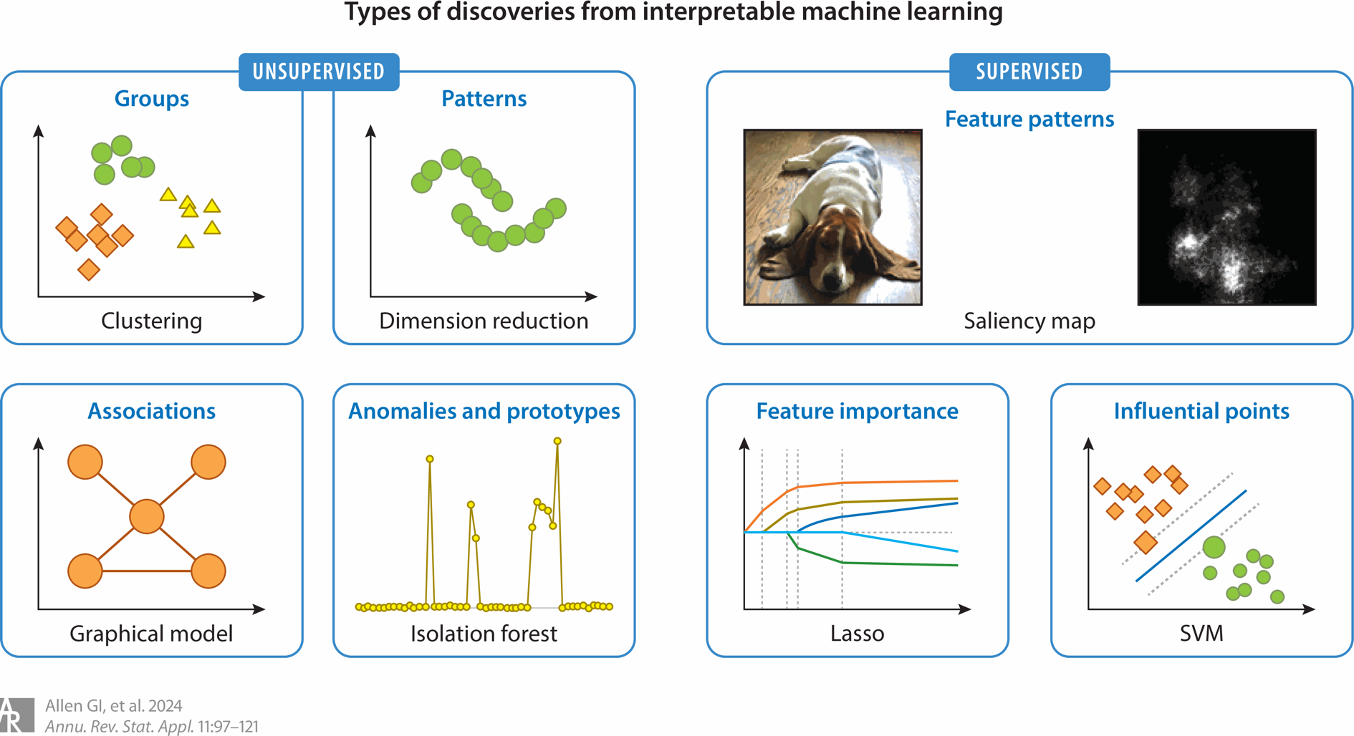
Recently, we have begun working on statistical challenges in interpretable machine learning. Our focus is on developing validation and uncertainty quantification strategies for machine learning interpretations including feature importance and unsupervised discoveries.
Key Publications:
- G. I. Allen, L. Gan, L. Zheng, ”Interpretable Machine Learning for Discovery: Statistical Challenges and Opportunities”, Annual Review of Statistics and its Application, 11:97-121, 2024. link
- L. Gan, L. Zheng, and G. I. Allen, “Model-Agnostic Confidence Intervals for Feature Importance: A Fast and Powerful Approach Using Minipatch Ensembles”, arXiv:2206.02088, 2022. link
Algorithmic Fairness
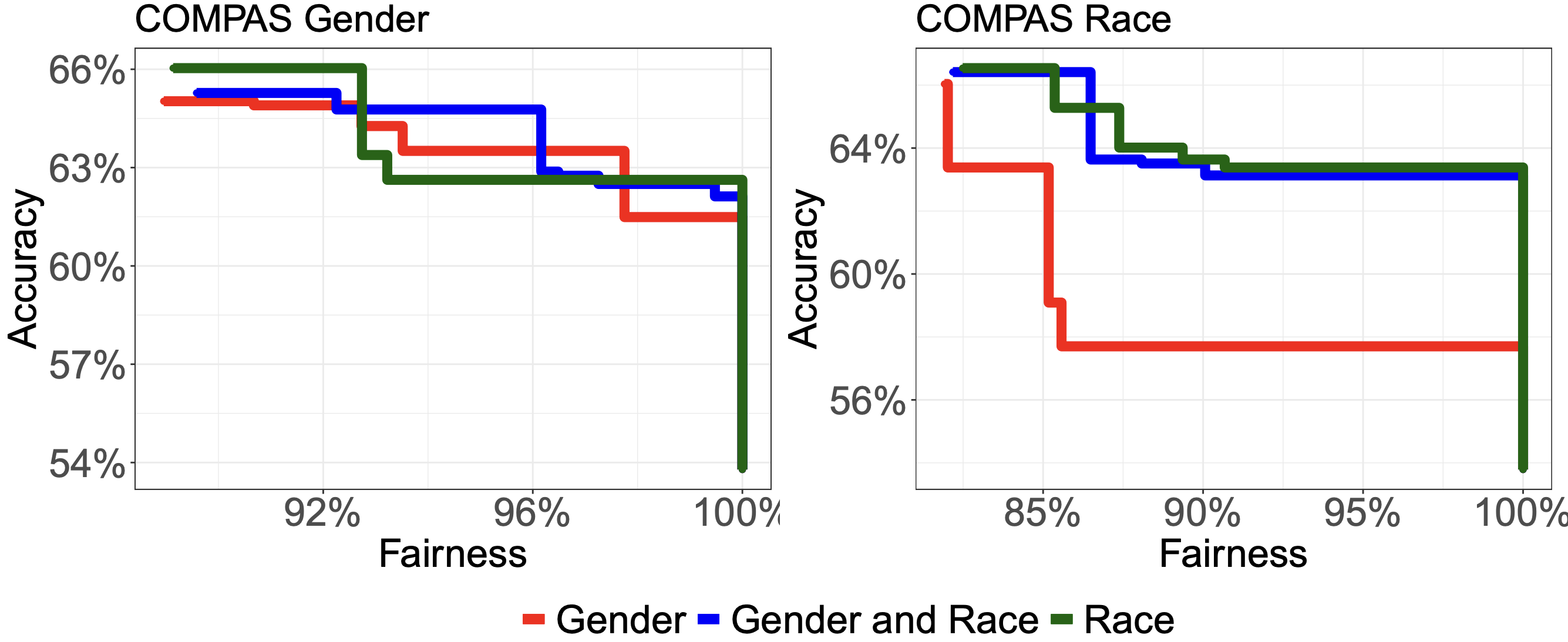
Machine learning algorithms can often inadvertently discriminate against certain subgroups by exacerbating subtle biases in historic data. Our recent work in the area of algorithmic fairness has sought to develop ways to audit and interpret bias mitigation strategies in machine learning.
Key Publications:
- C. O. Little, M. Weylandt, and G. I. Allen, “To the Fairness Frontier and Beyond: Identifying, Quantifying, and Optimizing the Fairness-Accuracy Pareto Frontier”, arXiv:2206.00074, 2022. link
- C. O. Little, D. H. Lina, and G. I. Allen, “Fair Feature Importance Scores for Interpreting Tree-Based Methods and Surrogates”, (To Appear), Transactions on Machine Learning Research, arXiv:2310.04352, 2024. link
- M. Navarro, C. O. Little, G. I. Allen, and S. Segarra, “Data Augmentation via Subgroup Mixup for Improving Fairness”, In IEEE International Conference on Acoustics, Speech, and Signal Processing, 7350-7354, 2024. link
Biomedicine
Genomics
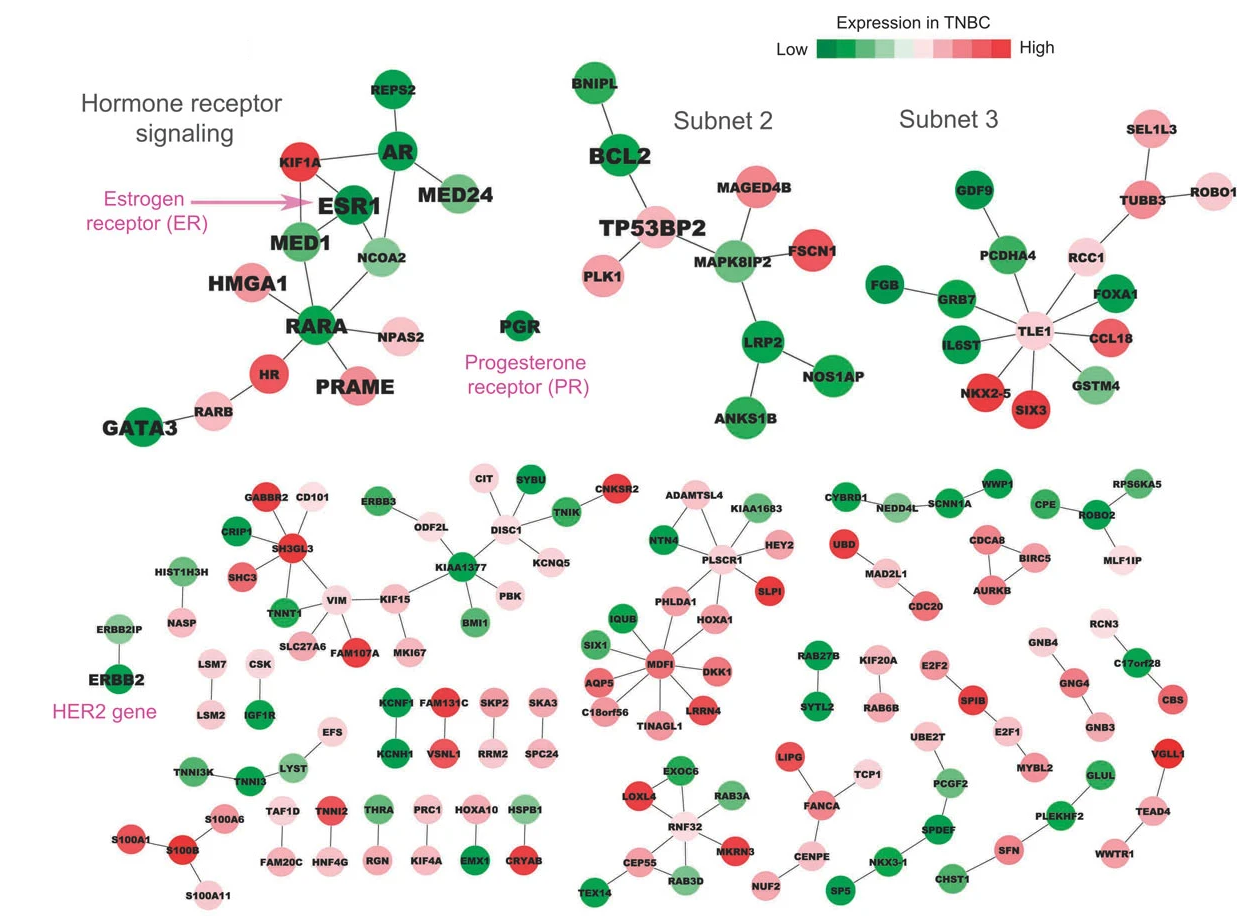
Much of our research program has been inspired by challenges in high-throughput genomics and multi-omics data. We have developed new statistical machine learning techniques and applied these to study genomic mechanisms in cancer and neurological diseases.
Key Publications:
- Y. W. Wan, G. I. Allen, and Z. Liu, “TCGA2STAT: Simple TCGA Data Access for Integrated Statistical Analysis in R”, Bioinformatics, 32:6, 952-954, 2016. link
- G. I. Allen and Z. Liu, “A Local Poisson Graphical Model for Inferring Networks from Next Generation Sequencing Data”, IEEE Transactions on NanoBioscience, 12:3, 1-10, 2013. link
- G. I. Allen and M. Maletic-Savatic, “Sparse Non-negative Generalized PCA with Applications to Metabolomics”, Bioinformatics, 27:21, 3029-3035, 2011. link
- L. Gan and G. I. Allen, “Fast and Interpretable Consensus Clustering via Minipatch Learning”, PLoS Computational Biology, 18:10, e1010577, 2022. link
- L. Gan, G. Vinci, and G. I. Allen, “Correlation Imputation for Single Cell RNA-seq”, Journal of Computational Biology, 29:5, 465-482, 2022. link